Cousera 《Algorithms II》课程作业
WordNet 由自于普林斯顿大学设计,是一种基于认知语言学的英语词典。综合了语言学,计算机等相关学科指示,按照词义将单词整理出同义词组和上下义关联关系,形成的一个网络。
WordNet Assignment
1、题目背景
1. WordNet
WordNet 由自于普林斯顿大学设计,是一种基于认知语言学的英语词典。综合了语言学,计算机等相关学科指示,按照词义将单词整理出同义词组和上下义关联关系,形成的一个网络。
一些概念
- 同义词集 - synsets:语义相同的一组单词
- 上义词 - hypernym:对事物的概括性、抽象性说明
- 下义词 - hyponym:对事物的具体表现形式或更为具体的说明
参考文献
2. BFS
广度优先搜索,利用队列(queue)实现的一种暴力搜索算法,最简便的图的搜索算法之一。
相比 DFS 利用栈结构(stack)递归进项搜索,容易理解,BFS 会更经常用于与“最小”/“最短”等关键词相关的图问题。
Dijkstra 单源最短路径算法和 Prim 最小生成树算法都采用了和宽度优先搜索类似的思想。
2、题目描述
总结为以下 4 点:
- 给定两个节点,寻找有向图中两个节点的最短距离&公共祖先
- 给出两个节点的集合,寻找两个集合中距离最短的两个节点的距离和公共祖先
- 给出两个输入文件,构建有向图
- 节点 id 所对应的同义词集 synsets.txt
- 词集间 id 的上下义关系 hypernyms.txt
- 给出一组词组,寻找这组词当中最无关的一项
3、文件结构
引用外部类 - algs4.jar
- Digraph.java
- BreadthFirstDirectedPaths.java
自身类
- SAP.java
- WordNet.java
- Outcast.java
4、解决思路
暴力求解引用外部类
1. SAP.java
SAP.java 主要完成利用 bfs 算法,在有向图中寻找共同祖先和最小路径长度的问题。构造函数输入该有向图,其中提供了两个 API length() 和 ancestor():
1 | public int length(int v, int w) { |
关于路径长度和祖先的定义,下图是个简单的示意。在一个有向图中,给定两个节点 v,w,则它们之间的 length 为两者都可到达某一个节点时,最小的边的数量,祖先节点即为该节点。当输入是两个节点的可迭代集合,表示寻找两个集合中拥有最短长度的两个节点的 length 和 ancestor。具体描述见:题目资料 链接
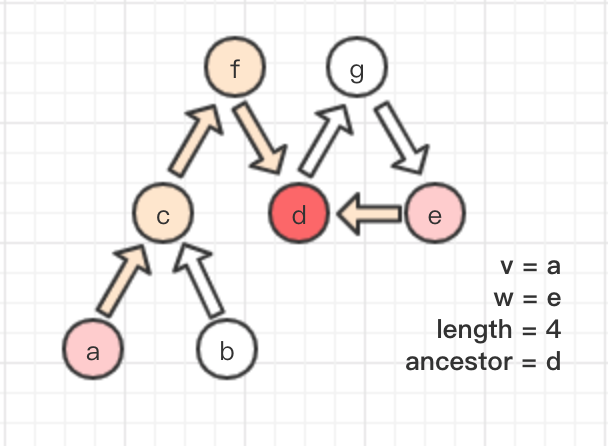
对于SAP.java的实现,这种方法使用到了官方 algs4.jar 包中的BreadthDirectedFirstPaths.java类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
> private void bfs(Digraph G, int s) {
> Queue<Integer> q = new Queue<Integer>();
> marked[s] = true;
> distTo[s] = 0;
> q.enqueue(s);
> while (!q.isEmpty()) {
> int v = q.dequeue();
> for (int w : G.adj(v)) {
> if (!marked[w]) {
> edgeTo[w] = v;
> distTo[w] = distTo[v] + 1;
> marked[w] = true;
> q.enqueue(w);
> }
> }
> }
> }
>
上面是 BreadthDirectedFirstPaths.java 中 bfs 的实现。marked[] 保存节点是否已经走过,distTo[] 记录从节点 s 到该节点的最短长度。这容易理解,因为广度优先,循环到当前节点即为最短路。普通的利用 queue 保存当前节点 v 的所有邻居,v 出队,v 的所有邻居判断完之后入队。如果输入为节点集合,则初始化 queue 时,需要把集合内所有节点入队。若节点 d 不可由 s 到达,marked[d]=false。
该版本 SAP.java 的基本思想是,对节点 or 节点集合 v 和 w 分别计算到其它所有点的最短路径。之后遍历一遍所有节点,判断是否同时可达 v 和 w,若可以则记录并更新 min length。主要由 bfsSearch() 方法完成。
2. WordNet.java
WordNet.java 主要完成从给定的同义词集 synsets.txt 和上义词关系 hypernyms.txt 中,构建有向图的功能。synsets.txt 中有三个域,每一个节点对应一个 id ,一个 id 映射到一个同义词集中,这个同义词集中包含多个词(word),最后一个域是对这一组词的解释,对于图的构建没有作用。hypernyms.txt 中给了节点间的指向关系,即有向图的边。
主要 API 如下:
1 | // is the word a WordNet noun? |
在 SAP.java 已经确定的情况下,这一部分仅为简单的输入字符串处理,构建有向图的过程,用到了 algs4.jar 中的 Digraph.java 类。输入两个词,寻找他们的共同上义词和距离,均可使用 SAP.java 中的方法。
节点对在这个版本中用了两个 map:一个 key 为 id,value 为对应的 synset。由于不涉及查找,这里可以直接用数组来优化;另一个 key 为单词,value 为该单词所在的节点的 list(因为一次多义,可能属于多个 id)。这个 map 用于 distance() 和判断单词是否属于该词典 isNoun() 两个 API。
3. OutCast.java
输入一组词,利用 WordNet.java 中的 distance() 方法计算每个词与其他词的距离之和。和最大的单词即为 OutCast。
问题&优化
1. Coding Styles
1) excessive boxing
初始代码中有这样一句报 warning:
1 | int id = Integer.valueOf(realms[0]); |
问题出于对装箱(boxing)这个概念不太了解,而且 java 中有自动装箱机制,平时没注意过。
装箱 就是把“值类型”转换成“引用类型”;对应的拆箱(unboxing)就是把“引用类型”转换成“值类型”。值类型一般来说是创建在栈中,引用对象的指针在栈中创建,实际对象则存于堆内存中。
怎么修改?由于 valueOf 返回的是 Integer 包装类,而 parseInt 返回的是 int 基本类型
In summary, parseInt(String) returns a primitive int, whereas valueOf(String) returns a new Integer() object.
2) new String() 和字面量赋值
初始化 String 变量时有这样一个 warning
1 | String outcast = new String(); |
nice! 因为这个问题又复习了一遍 JVM。正式运行程序时,.class 文件中的大部分数据被加载到运行时常量池中。此时字符串本体仍被创建在堆内存中。而在永生代方法区之外,保存有一个字符串常量池,里面储存该字符串对象的引用。使用字面量创建时,虚拟机会先从字符创常量池中找是否有值相等的引用,如果有则返回这个引用。
1 | String str1 = "string"; |
所以以上 str1 和 str2 的指向同一个堆内存地址,str3 在堆中申请了新的地址创建新的对象。
下面的资料生动形象地说明发生了什么:
3) final 变量的使用
需要考虑变量不发生变化时,使用 final 修饰符提高性能。
2. Edge cases
1) null 的判断
输入参数是 list 是,注意判断内部元素是否为 null
2)immutable 的 SAP.Java
这里有要求说 SAP.java 类需要是不可变的,但是构建时使用了 Digraph 类是可变的,因此需要 new 一个拷贝,不能直接引用。
3)rooted DAG
要求判断输入的图是否是只有一个根的有向无环图。根据每个节点的出度判断。
3. 优化
在 bfs 中可以对两个节点轮询查找,找到共同祖先后终止循环,减少循环次数。参考https://www.cnblogs.com/mingyueanyao/p/9166441.html
综上,code 详见:👉here
5、总结
- 了解了 WordNet 及语义处理的基本概念
- 加深理解有向图结构及方法
- 加深理解 BFS 算法
- 积累 null 及相关边界条件处理经验
- 熟悉 java 装箱 拆箱机制
- 复习 final 关键字的用法
- 复习了 jvm 基本知识